NLP 模型发展简要史:从 bags of words 到 Transformer 家族
速览
本文全面概述了自词袋模型到Transformer家族的自然语言处理(NLP)模型的发展历程。它提供了包括词袋、TF-IDF、Word2Vec、RNN、Transformer、BERT、GPT、RoBERTa、XLM、Reformer、ELECTRA、T5等关键模型在内的时间轴,这些模型已经在多年的时间内塑造了这个领域。作者对每个模型进行了个人概述,讨论了它的工作原理、特点和局限性。
原文链接:
A brief timeline of NLP from Bag of Words to the Transformer family
A Brief Timeline of NLP from Bag of Words to the Transformer Family
BOW, TF-IDF, Word2Vec, Transformer, BERT, GPT, RoBERTa, XLM, Reformer, ELECTRA, T5, and many others
Hello fellow NLP enthusiasts! As the race towards finding better and better neural networks for language modeling continues, I thought it might be a good time to get an overview of the progress made over the years. Enjoy! 😄
Disclaimer: This article is not a complete list of research done in NLP, which would struggle to fit even in several books! Rather, it is a personal overview of some of the models that have influenced the research of the field. I’ll try to make it simple and not simplistic as much as I can, therefore take the article as a starting point to delve into the field.
That said, here is the list of models!
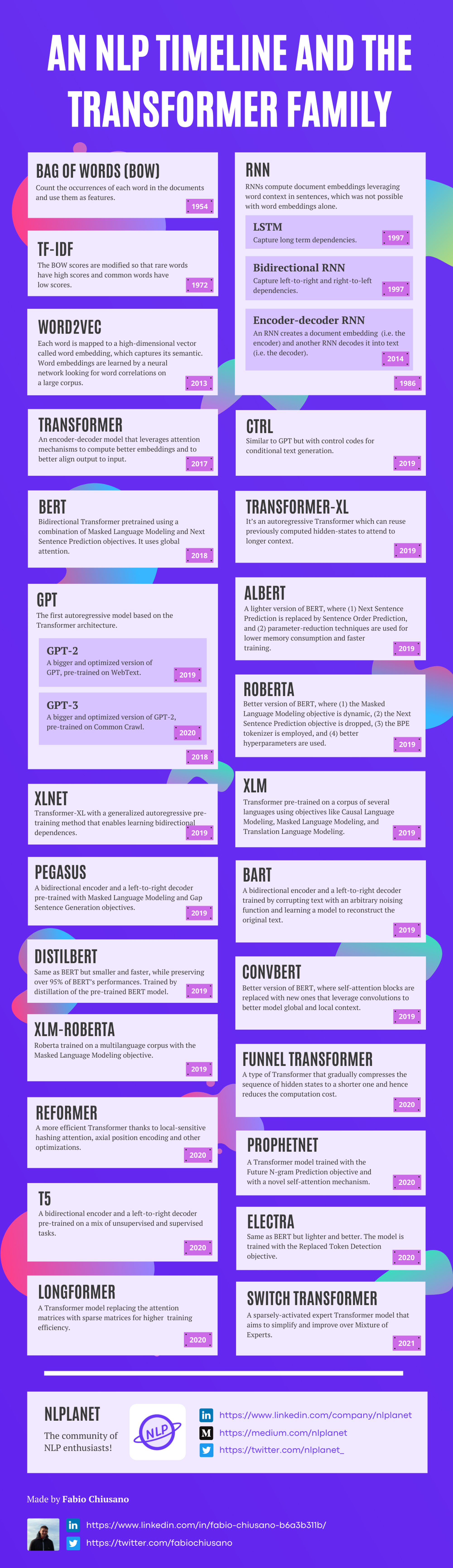
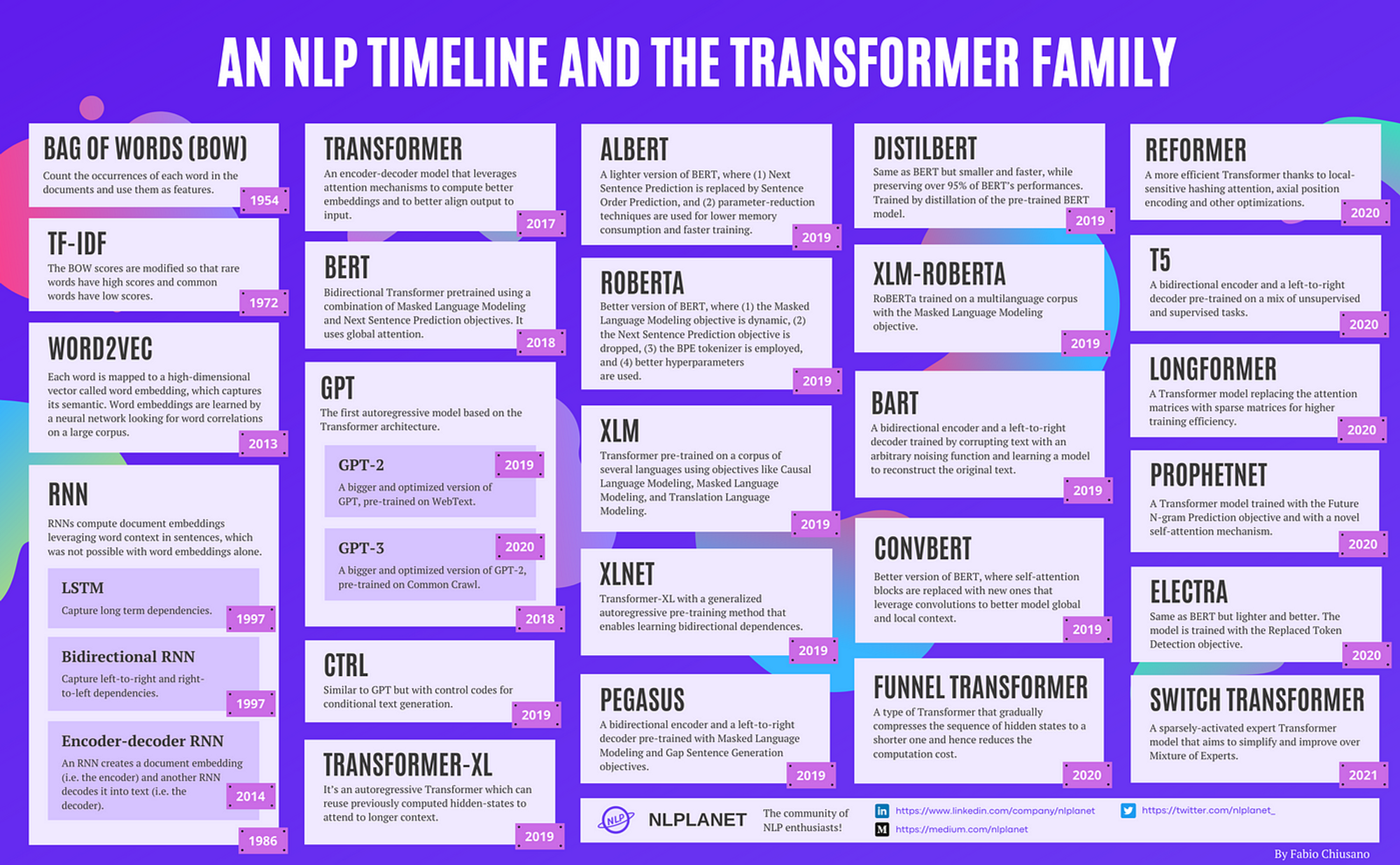
- Bag of Words (BOW) [1954]: count the occurrences of each word in the documents and use them as features.
- TF-IDF [1972]: the BOW scores are modified so that rare words have high scores and common words have low scores.
- Word2Vec [2013]: each word is mapped to a high-dimensional vector called word embedding, which captures its semantic. Word embeddings are learned by a neural network looking for word correlations on a large corpus.
- RNN [1986]: RNNs compute document embeddings leveraging word context in sentences, which was not possible with word embeddings alone. Later evolved with LSTM [1997] to capture long-term dependencies, and to Bidirectional RNN [1997] to capture left-to-right and right-to-left dependencies. Eventually, Encoder-Decoder RNNs [2014] emerged, where an RNN creates a document embedding (i.e. the encoder) and another RNN decodes it into text (i.e. the decoder).
- Transformer [2017]: an encoder-decoder model that leverages attention mechanisms to compute better embeddings and to better align output to input.
- BERT [2018]: bidirectional Transformer pre-trained using a combination of Masked Language Modeling and Next Sentence Prediction objectives. It uses global attention.
- GPT [2018]: the first autoregressive model based on the Transformer architecture. Later evolved into GPT-2 [2019], a bigger and optimized version of GPT pre-trained on WebText, and GPT-3 [2020], a further bigger and optimized version of GPT-2, pre-trained on Common Crawl.
- CTRL [2019]: similar to GPT but with control codes for conditional text generation.
- Transformer-XL [2019]: it’s an autoregressive Transformer that can reuse previously computed hidden-states to attend to longer context.
- ALBERT [2019]: a lighter version of BERT, where (1) Next Sentence Prediction is replaced by Sentence Order Prediction, and (2) parameter-reduction techniques are used for lower memory consumption and faster training.
- RoBERTa [2019]: better version of BERT, where (1) the Masked Language Modeling objective is dynamic, (2) the Next Sentence Prediction objective is dropped, (3) the BPE tokenizer is employed, and (4) better hyperparameters are used.
- XLM [2019]: Transformer pre-trained on a corpus of several languages using objectives like Causal Language Modeling, Masked Language Modeling, and Translation Language Modeling.
- XLNet [2019]: Transformer-XL with a generalized autoregressive pre-training method that enables learning bidirectional dependences.
- PEGASUS [2019]: a bidirectional encoder and a left-to-right decoder pre-trained with Masked Language Modeling and Gap Sentence Generation objectives.
- DistilBERT [2019]: same as BERT but smaller and faster, while preserving over 95% of BERT’s performances. Trained by distillation of the pre-trained BERT model.
- XLM-RoBERTa [2019]: RoBERTa trained on a multilanguage corpus with the Masked Language Modeling objective.
- BART [2019]: a bidirectional encoder and a left-to-right decoder trained by corrupting text with an arbitrary noising function and learning a model to reconstruct the original text.
- ConvBERT [2019]: a better version of BERT, where self-attention blocks are replaced with new ones that leverage convolutions to better model global and local context.
- Funnel Transformer [2020]: a type of Transformer that gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost.
- Reformer [2020]: a more efficient Transformer thanks to local-sensitive hashing attention, axial position encoding, and other optimizations.
- T5 [2020]: a bidirectional encoder and a left-to-right decoder pre-trained on a mix of unsupervised and supervised tasks.
- Longformer [2020]: a Transformer model replacing the attention matrices with sparse matrices for higher training efficiency.
- ProphetNet [2020]: a Transformer model trained with the Future N-gram Prediction objective and with a novel self-attention mechanism.
- ELECTRA [2020]: same as BERT but lighter and better. The model is trained with the Replaced Token Detection objective.
- Switch Transformers [2021]: a sparsely-activated expert Transformer model that aims to simplify and improve over Mixture of Experts.
Here is an infographic highlighting all the models cited in this article.